Пошуківець
Енциклопедія від Google
Submitted by Yuriy Syerov on Sun, 16/12/2007 - 15:56Google вирішив створити свою енциклопедію, яка має стати аналогом та конкурентом Wikipedia.
Цікавим мені видався факт, що автори статей зможуть заробляти на контекстній рекламі, яка буде розміщена на сторінках з їхніми статтями. Цікаві статті матимуть хорошу відвідуваність. А це значить, що автори цікавих статей, зароблятимуть гроші.
Думаю, така ідея має гарні перспективи, бо гроші, хоч і невеликі більше стимулюватимуть до написання якісних статей. Крім того між авторами виникне конкуренція, щоб саме їхня стаття була розміщена в енциклопедії.
З іншого боку, зрозуміло, що автори будуть "битися" лише за "топові" теми, в той час як непопулярні теми можуть залишатися невисвітленими взагалі.
Google Labeler. ШІ для ШІ версія друга.
Submitted by Andriy Peleschyshyn on Thu, 23/08/2007 - 00:02Ось тут Штучний інтелект для штучного інтелекту на нашому сайті Сергієм Адамчуком уже піднімалося питання того, що штучний інтелект потребує не раз зовнішньої підтримки, яка приходить у формі залучення рядових користувачів Інтернету до виконання рутинно-інтелектуальних дій. Такий собі "Штучний інтелект для штучного інтелекту". У першу чергу це стосується задач розпізнавання графічних образів.
Звичайно, такий підхід вимагає мотивації користувачів. А платити ніхто не хоче. І тоді замість матеріальної мотивації використовується, скажемо так, слабкість людського духу.
Мені відомі випадки, коли такі задачі доручалися людям взамін за доступ до порно ресурсів. Тобто для входу в закриту зону сайту з порноконтентом користувач повинен був розпізнати капчу або щось подібне, яка насправді не була оригінальною капчою порносайту, а зображенням з якогось сайту, де вона була бар'єром на шляху бота. Коли користувач правильно розпізнавав капчу, бот виконував свою "чорну" справу, а користувач добирався до такого бажаного контенту.
Але виявляється, хіть не єдина людська слабкість, що дає можливість запрягти людину у таку специфічну діяльність. Азарт - ось наступна вада людини, що стала використувуватися у подібних задачах.
Проте, на цей раз, азарт користувачів використовують не якісь безіменні хакери чи бездушні боти, а, як це не дивно, сам Google. Як це відбувається і для чого? Якщо вам цікаво подивитися, то вам сюди - http://images.google.com/imagelabeler/
Мета-таг unavailable_after. Новий стандарт від Google
Submitted by Andriy Peleschyshyn on Mon, 30/07/2007 - 10:23Google знову задає новий стандарт для пошукових систем.
Після появи ряду нових технологій та розширень, зокрема технології sitemap, це вже стає доброю традицією.
На цей раз Google пропонує певний контроль за часом зберігання сторінки в кеші пошукової системи. З цією метою він уводить новий мета-таг unavailable_after.
Суть нововедення наступна. Даним тегом Веб-майстер може зазначити, доки дана сторінка зберігатиме актуальність і відповідно, доки її доцільно зберігати в БД пошукової системи.
Ось приклад такого визначення
Як відзначають аналітики на тематичних блогах і форумах, особливо цінним даний таг є для електронних магазинів, де таким чином можна описувати актуальність розміщених пропозицій (щоби вони потім не уводили в оману у результатах пошуку Google), та для різного роду видань, у яких є безкоштовні та платні розділи. Наприклад, цей таг може стати у пригоді, якщо планується переміщення матеріалу з безкоштовної в платну зону.
Google Desktop для платформи Linux
Submitted by Andriy Peleschyshyn on Mon, 02/07/2007 - 21:08Приємна новина для користувачів Лінукса на робочих станціях. Google випустив у світ свій популярний пошук по локальному комп'ютеру Google Desktop для платформи Linux. Раніше свою популярність Google Desktop набував на машинах з Windows.
Такий крок знову ж свідчить про підтримкою Google платформи Linux, проте сам Google Desktop до відкритого ПЗ не відноситься.
Розробники стверджують, що підтримуються версії Debian 4.0, Fedora Core 6, Ubuntu 6.10, Novell Suse 10.1 та Red Hat 5. Графічний інтерфейс працює під KDE та GNOME.
Лежить даний програмний продукт тут http://desktop.google.com/linux
Google надасть статистику пошукових запитів американській владі
Submitted by Yuriy Syerov on Tue, 14/03/2006 - 18:25Міністерство юстиції США в судовому проядку зобов'язало Google надати статистику пошукових запитів. Зробити це вони мають протягом 21 дня.
За офіційною версією міністерства, ця інформація їм потрібна для контролю за поширенням порнографії, зокрема дитячої.
Статистику планують використати для тестування системи фільтрації контенту, котре почнуть проводити восени.
Інші пошуківці надали таку статистику раніше, лише Google відмовлявся це робити.
Схоже, гарантії на приватність інформації користувачів, яку давав Google, зруйнувала американська влада...
Джерело:
Google предоставит статистику поисковых запросов...
Технологія AJAX та пошукові системи
Submitted by Andriy Peleschyshyn on Fri, 17/02/2006 - 22:39Технологія AJAX стрімко увірвалася в типовий набір технологій формування Веб-сторінок і зараз набуває ще більшої популярності.
Вперше користувачі близько познайомилися з AJAX в новій пошті Google Mail (Gmail) і були вражені високою інтерактивністю Веб-сторінок та їхньою “легкістю” під час змін. Фактично, по інтерактивності такі сторінки вже більше співмірні з локальними програмами “офісного” класу ніж з традиційними HTML-сторінками.
Я не буду зараз вдаватися в деталі технології (це тема для окремого матеріалу, і сподіваюся, що такий матеріал в нас на сайті ще зявиться), відмічу коротко що суть технології наступна. Браузер, окрім статичного HTML разом зі сторінкою підтягує досить хитрий JavaScript код, який постійно тримає звязок зі сервером, отримує потрібні інструкції зі сервера, і відповідно до них модифікує код сторінки (сторінка видозмінюється).
Детальніше про технологію можна почитати наприклад тут http://en.wikipedia.org/wiki/Ajax_%28programming%29
У цій статті мова дещо про інше. Річ у тім, що окрім броузерів сторінки сайту “переглядають” і роботи пошукових систем. А для них звичайно AJAX не значить нічого, і замість AJAX-сторінок вони бачать пусте місце, або стартовий статичний HMTL-код сторінки.
Тут і виникає певна проблема. Попри всю зручність і ефектність сайт виконаний по технології AJAX може для пошукової системи бути пустим місцем. Тобто відвідувачі на сайт з пошуківців потрапляти не будуть. А таку розкіш можуть дозволити далеко не всі власники сайтів.
Коли я вперше познайомився з AJAX, моя думка щодо технології з наведеної вище причини була цілком негативною.
Проте, при детальнішому розгляді стає зрозуміло, що не все так погано. Більше того, використання AJAX для деяких типів сайтів за певних умов може стати навіть корисним з точки зору позиціонування в пошукових системах.
Якоб Нільсен: “Пошукові системи – пиявки на тілі Вебу”
Submitted by Andriy Peleschyshyn on Sun, 15/01/2006 - 00:18Невелика стаття провідного фахівця з юзабіліті Веб-сайтів Якоба Нільсена Search Engines as Leeches on the Web уже встигла трохи наробити шуму.
Як і багато інших теоретиків та практиків Веб-технологій, Якоб Нільсен звернув увагу на те, що пошукові системи часто позбавляють користувача потреби заходити на сайт, з якого отримано інформацію.
Нільсен стверджує, що має місце тенденція до зміни характеру запитів користувачів до пошукових машин в напрямку конкретизації. Як наслідок, часто користувач задовольняє свою інформаційну потребу, просто переглядаючи результати пошуку. Важко сказати, наскільки правий Нільсен, але слід мати на увазі, що він має серйозну аналітичну службу, яка досліджує поведінку людей у Вебі.
Відзначу також, що деякі аналогічні проблеми взаємодії пошукових машин та інших сайтів уже обговорювалися на ІТ-Аналітика (зокрема ось тут - Пошукові системи та інтелектуальна власність )
У своїй статті Нільсен фактично декларує необхідність виходу сайтів з під залежності від пошукових систем.
У завершальній частині статті автор пропонує власникам сайтів ряд механізмів, які мають допомогти звільнитися від такої залежності. Це зокрема наступні засоби:
Google Base - новий сервіс від Google
Submitted by Andriy Peleschyshyn on Sun, 20/11/2005 - 22:42Google запустив в роботу новий сервіс – Google Base http://base.google.com
Основне призначення сервісу – онлайн база даних понять кількох різних категорій.
У чомусь цей сервіс мені нагадав Енциклопецію Яндекса.
Особливістю Google Base є можливість поповнення бази даних користувачами. Сервіс інтегровано з іншими службами Google. Якість пошуку так собі – вочевидь залежить від предмету пошуку. Так, по товарах пошук гарний, а по слову Lviv http://base.google.com/base/search?q=lviv&btnG=Search+Base&nd=0&scoring=r&us=0
– не дуже, єдиною світлиною, асоційованою зі Львовом виявилася знимка спина Максима Антоневича, адміна УАРНету і якоїсь пані з ним. Не зовсім зрозуміло, чому ця світлина туди потрапила.
Пошук по акронімах
Submitted by Andriy Peleschyshyn on Fri, 10/06/2005 - 23:25З'явився спеціалізований пошуковий сервіс для пошуку акронімів та абревіатур. Адреса - http://www.acronyma.com/
Пишуть, що їхня база понад 450 тисяч термінів.
1-квітневий "жарт" Яндекса - халява за чужий рахунок
Submitted by Andriy Peleschyshyn on Fri, 08/04/2005 - 12:57Увесь рунет кипятком від радості обливався з приводу жарту Яндекса, який імітував вивід сайту на перше місце у видачі. Особливо дана мулька була популярна серед оптимізаторів.
Радості неміряно - свій сайт на перше місце по крутому слову на Яндекс вивести.
Навіть у нас на Форумі таким захоплювалися. Форум і Яндекс - Інтернет та мережі - Львів. Форум Рідного Міста
А ніхто не задумався, що Яндекс за один день набив собі базу сайтів, над якими працюють оптимізатори?
І що він тепер буде з тою базою робити?
Якщо дурні - то викинуть і забудуть. Якщо мудрі - то отримають серйозний матеріал для аналізу та моніторингу.
Гарний жарт - і людям радість і собі користь. Правда, чи буде користь саме тим, кому радість - сумніваюся
Пошукові системи та інтелектуальна власність
Submitted by Andriy Peleschyshyn on Mon, 21/03/2005 - 11:13Усе частіше пошукові системи та інші системи агрегації інформації з інтернету стають об’єктами переслідування за порушення інтелектуальної власності.
На цей раз “під обстріл” знову попав Гугл – Франс Прес подало в суд позов сумою 17 млн доларів на Гугл за порушення копірайту при републікації на своїй службі Google News новин агенства. http://news.com.com/2100-1030_3-5626341.html
Нагадаю, що дана служба автоматично агрегує новини з різноманітних джерел, рангує їх, і найважливіші виводить на чільні сторінки та забезпечує можливість тематичного пошуку по новинах.
Основними напрямками, по яких виникають проблеми глобальних сервісів з копірайтом є:
- Результати пошуку по “брендах”
- Контекстна реклама по “брендах”
- Видача та кешування інформації, що захищена копірайтом
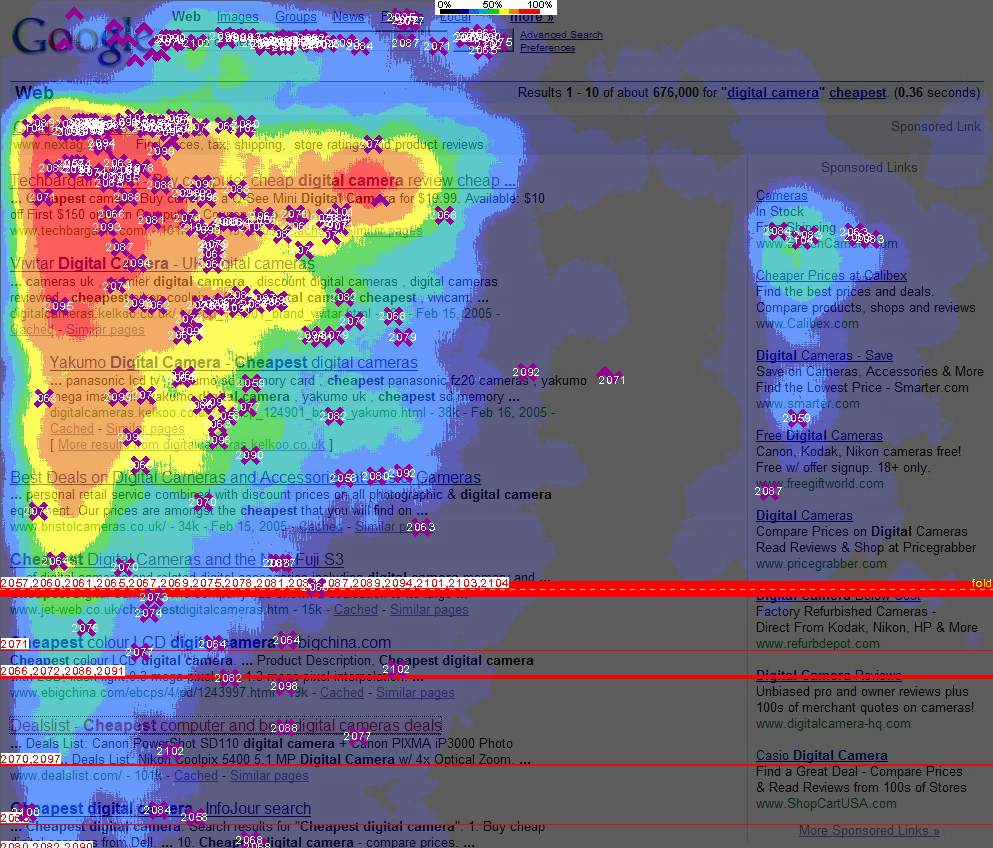
Як людина переглядає сторінку Google
Submitted by Andriy Peleschyshyn on Tue, 08/03/2005 - 21:32Проценти користувачів які переглянули відповідні позиції результатів пошуку на Гугл, перша сторінка:
* Rank 1 - 100%
* Rank 2 - 100%
* Rank 3 - 100%
* Rank 4 - 85%
* Rank 5 - 60%
* Rank 6 - 50%
* Rank 7 - 50%
* Rank 8 - 30%
* Rank 9 - 30%
* Rank 10 - 20%
Проценти користувачів які переглянули відповідні позиції комерційної реклами на Гугл, перша сторінка:
* Sponsored listing 1 - 50%
* Sponsored listing 2 - 40%
* Sponsored listing 3 - 30%
* Sponsored listing 4 - 20%
* Sponsored listing 5 - 10%
* Sponsored listing 6 - 10%
* Sponsored listing 7 - 10%
* Sponsored listing 8 - 10%
та відповідна ілюстрація screen shot of the triangle.
{kind=link}
Порівняння двох програм для локального пошуку
Submitted by Andriy Peleschyshyn on Sun, 06/03/2005 - 00:52У звязку з катастрофічним ростом об'єму інформації на персональному комп'ютері вирішив поекспериментувати з ПЗ для локального пошуку.
Спробував спочатку Google Desktop Search а потім Kopernic Desktop Search.
Висновок очевидний - перевага на боці Коперніка. За Гуглом - тільки голосна назва фірми-виробника.
Дивіться самі:
Продовжується використання пошуківців шкідливим ПЗ
Submitted by Andriy Peleschyshyn on Fri, 18/02/2005 - 01:13Намітилися прогнозована тенденція до активного використання глобальних пошукових машин (таких як Гугл) шкідливим ПЗ, в першу чергу хробаками, які шукають жертв для атаки
Тепер цим займається нова версія хробака MyDoom
New MyDoom worm uses search engines to spread: Internet News: The Industry Standard
В своїй діяльності вірус користає послугами Google, Lycos, Yahoo
Гугл відмовляється виконувати деякі запити
Submitted by Andriy Peleschyshyn on Mon, 14/02/2005 - 22:41Гугл відмовляється виконувати деякі спеціальні запити, зокрема allinurl для деяких типів сторінок (наприклад php). У відповідь він повідомляє, що імовірно комп'ютер інфіковано вірусом або спайваре.
Імовірно, це відголосок недавньої історії з масовим взламом PHPBB форумів ( Хробак, який нищить phpBBфоруми | Журнал "Інформаційні технології. Аналітичні матеріали". ), або захист від подібних дій на майбутнє
Приклад запиту -
http://www.google.com.ua/search?hl=uk&q=allinurl%3Amisto.ridne.net%2Findex.php&btnG=%D0%9F%D0%BE%D1%88%D1%83%D0%BA&meta=
Текст відмови
... but we can't process your request right now. A computer virus or spyware application is sending us automated requests, and it appears that your computer or network has been infected.
We'll restore your access as quickly as possible, so try again soon. In the meantime, you might want to run a virus checker or spyware remover to make sure that your computer is free of viruses and other spurious software.
Нове значення атрибуту REL гіпертекстового посилання від Google
Submitted by Andriy Peleschyshyn on Fri, 21/01/2005 - 19:32Тепер Google зайнявся вдосконаленням мови HTML – додав до списку можливих значень атрибуту rel тегу А значення nofollow (зі самим списком допустимих значень можна ознайомитися тут - Basic HTML data types ).
Google Scholar - науковий пошук
Submitted by Dmitriy Tarasov on Thu, 18/11/2004 - 22:42Google Scholar - пошукова система від Google, яка здійснює пошук у тематичних матеріалах. Орієнтована на науковців та студентів.
Переклад Google на українську
Submitted by Sergi Adamchuk on Mon, 30/08/2004 - 10:11Гугл бере активну участь у перекладі своїх продуктів на інші мови.
Вже давно перекладено основну пошукову машину та основні сервіси на українську. На даний момент триває українізації Google Toolbar.
Причому кожен користувач може зробити свій як завгодно малий чи великий вклад у цю справу.
Кожен доброволець інтерактивно одержує маленьку порцію тексту для перекладу, та короткий опис про те, де з'являється цей текст. Таким чином паралельно може працювати над перекладом довільна кількість користувачів. Навіть якщо ви перекладете хоча б одну фразу - ви все одно зробите немалий вклад.
Крім перекладу нових текстів можна вносити корективи у існуючі, тобто, якщо ви десь зауважите у продуктах Google неточність - ви завжди зможете самі виправити це.
Open Directory Project - коротка інформація
Submitted by Andriy Peleschyshyn on Sun, 22/08/2004 - 01:34Стаття про один з визначальних Інтернет-проектів сучасності - Open Directory Project
Добре відомо, що World Wide Web є величезним масивом інформації, який охоплює більшу частину усього, що сотворило людство на сьогоднішній день. Проте, одна з найбільших проблем, що стоїть на заваді повноцінному використанню WWW є складність пошуку у ньому потрібної інформації. Розв’язанню цієї задачі покликані служити пошукові машини та каталоги ресурсів Інтернету.
Фактично, більша частина ресурсів WWW на сьогодні знаходиться користувачами Інтернет не через різні види реклами сайту, а безпосередньо з каталогів або з пошукових машин. Далі ми розглянемо найважливіший існуючий каталог сайтів – ODP
Recent comments
14 years 33 weeks ago
14 years 35 weeks ago
15 years 17 weeks ago
15 years 24 weeks ago
16 years 10 weeks ago
16 years 33 weeks ago
16 years 39 weeks ago
16 years 44 weeks ago
16 years 47 weeks ago
17 years 9 weeks ago